À propos de l'outil
Introduction
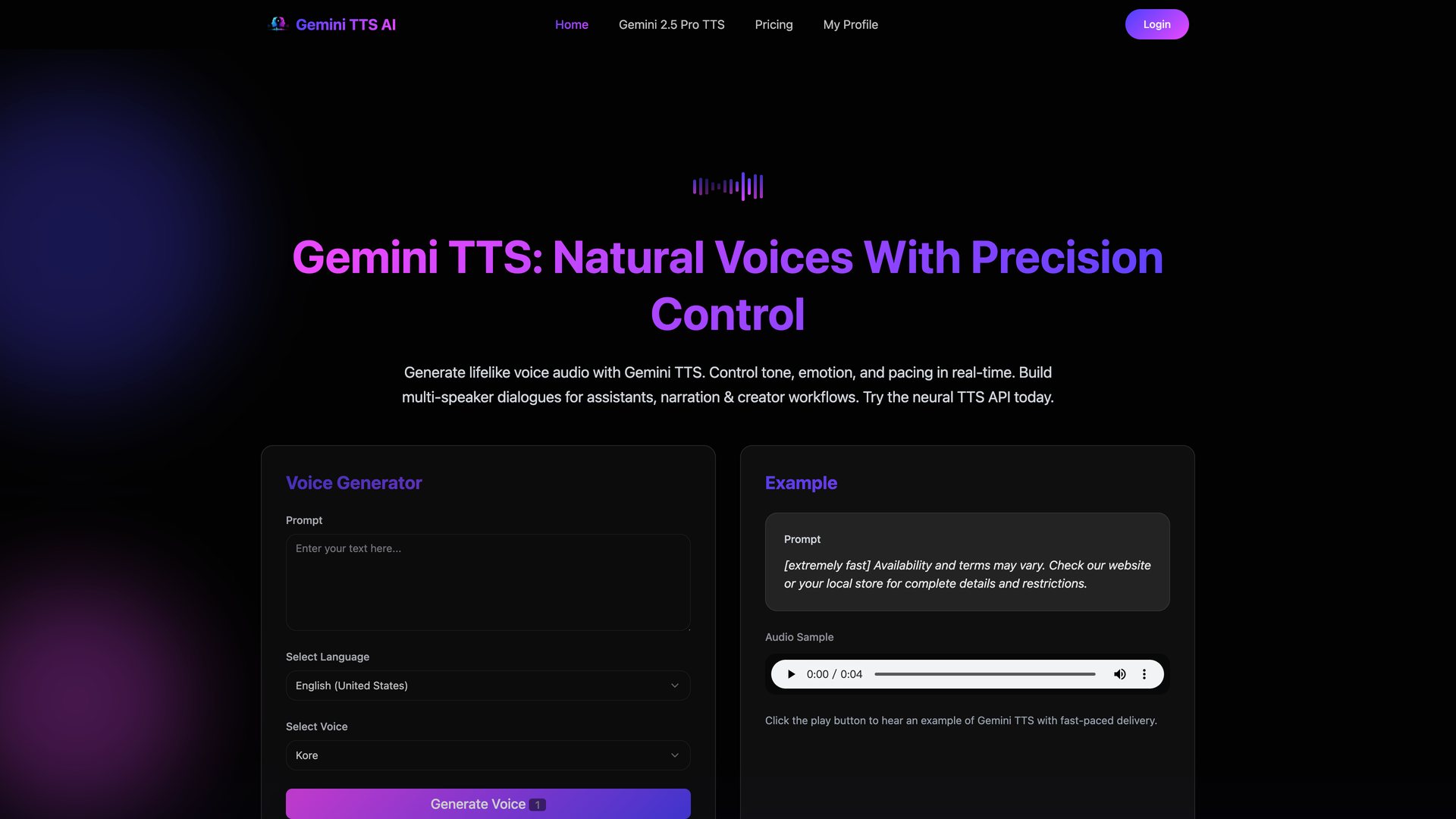
What is Gemini TTS?
Gemini TTS is a modern, AI-powered text-to-speech solution designed to generate lifelike, natural-sounding audio from text. It stands out by allowing users to direct the vocal performance using simple, plain-English instructions for tone, pace, emotion, and role, eliminating the need for complex audio parameter tweaking.
Core Purpose and Target Audience
Built for predictability and control, Gemini TTS serves a wide range of users including content creators, developers, educators, and businesses. Its core purpose is to enable the creation of brand-consistent, engaging, and high-quality voice experiences for applications ranging from real-time voice assistants and audiobooks to e-learning modules and marketing videos.
Features
Expressive Style and Tone Control
Guide the vocal performance using natural language prompts such as "cheerful," "calm," "serious," or "cinematic." Gemini TTS is engineered to adhere strictly to these style instructions, ensuring your audio output remains on-brand and role-consistent across all content.
Precision Pacing and Rhythm
Control the delivery speed and rhythm to match the context—whether for jokes, suspense, tutorials, or disclaimers. The tool supports context-aware pacing, allowing for requests like faster delivery, slower emphasis, or gradual shifts in energy, which it executes reliably for a natural sound.
Multi-Speaker Dialogue Generation
Create believable conversations for podcasts, interviews, game characters, or training simulations. Gemini TTS supports multi-speaker scenarios with smooth handoffs, maintaining a stable and distinct voice for each character throughout the dialogue.
Multilingual Speech with Personality Preservation
Generate speech in multiple languages while maintaining the core tone, pitch, and style of the speaker. This feature is essential for global products, helping content feel local and authentic rather than mechanically translated.
Flexible Quality and Latency Options
Choose between options optimized for low-latency (ideal for real-time interactive applications) and options optimized for premium audio quality (perfect for polished, final content like audiobooks and videos).
Granular Control for Accents and Pronunciation
Exercise fine-grained control over accents, the pronunciation of technical terms, and the delivery of tricky words. This ensures the final audio sounds intentional and professional, not generic.
Developer-Friendly API Integration
Scale from prototyping to production with a straightforward API. Gemini TTS supports seamless integration into developer workflows, enabling teams to build and iterate on voice experiences quickly.
Frequently Asked Questions
What is Gemini TTS?
Gemini TTS is an advanced text-to-speech solution that converts written text into high-fidelity, natural-sounding audio. It provides detailed control over vocal characteristics like tone, pacing, style, accents, and enables the creation of multi-speaker dialogues.
What makes Gemini TTS different from traditional TTS?
Unlike traditional TTS systems that often produce flat, robotic speech, Gemini TTS uses AI to generate expressive, human-like voices. Its key differentiator is the precise control offered through natural language prompts, allowing users to dictate emotion, pacing, and style directly.
Can Gemini TTS generate multi-speaker conversations?
Yes. A core feature of Gemini TTS is its ability to create realistic multi-speaker dialogues. It can maintain consistent and distinct character voices across a conversation, making it ideal for podcasts, audio dramas, training simulations, and customer service scenarios.
Can I control speed and pauses with Gemini TTS?
Absolutely. Gemini TTS offers precision pacing control. You can instruct the AI to deliver text faster, slower, or with specific pauses to create the desired rhythm and emphasis, which is crucial for narration, jokes, or important disclaimers.
Does Gemini TTS support different tones like "cheerful" or "serious"?
Yes. You can control the expressive style by using prompts such as "cheerful," "calm," "serious," "cinematic," "friendly," or "dramatic." The system is built to follow these style directives closely.
Is Gemini TTS good for real-time applications?
Yes. Gemini TTS includes low-latency generation options specifically optimized for real-time applications where immediate responsiveness is critical, such as in voice assistants and interactive customer support systems.
How does Gemini TTS handle accents and localization?
Gemini TTS is designed for granular control over accents and supports multilingual generation. This allows for the creation of localized content that preserves the intended personality and tone of the speaker, making it sound natural to native listeners.
How do I get started with Gemini TTS?
You can start by generating your first audio clip on the website. For broader integration, you can explore the developer-friendly API to build Gemini TTS into your own applications and workflows.